

In this article, you are going to learn about a core AWS service, called Simple Storage Service. AWS Simple Storage Service, or S3, is a very versatile and useful service. It is also one of the oldest AWS services. That means it is one you should know, especially for the exam.
Therefore, let us start by looking at some of the use cases for this service.
AWS S3 use cases
Some of the use cases for AWS S3 are as follows:
- Static Website Hosting => You can use S3 to store static websites like Gatsby.
- Archive Data => You can archive terabytes of data at low costs thanks to S3 Glacier.
- Backups => As you will see later in the article, S3 provides maximum durability and availability. That means it is a perfect place to store your backups.
- Website assets => You can store your website assets such as logos, media, photos, videos, and so on.
What is AWS S3?
First of all, the full name is Simple Storage Service. Thus, to shorten the name, they simply call it S3 because of the three S.
S3 is one of the oldest and most fundamental AWS services. This service allows you to store and retrieve any amount of data from anywhere in the world. In simpler words, it is a hosting service where you can store your flat files. By flat files, I mean files that do not change—for instance, pictures, videos and so on. Thus, you cannot store a database on S3 because it is continuously changing.
Objects and Buckets
S3 is an object storage service, which means that the objects are stored in buckets. A bucket is another term for a directory, and an object is another term for a file. An object (file) contains the following information:
- key => the name of the file
- value => the content of the file
- version ID => when versioning is on
- metadata => additional data about the object
Each bucket can contain multiple objects, and each bucket can contain other folders which in turn hold other objects. Also, each bucket has a unique name. Think of it like a domain name: there cannot be two websites with the same name. As a result, your bucket name must be unique.
Therefore, let us quickly recap. AWS S3 is a storage service which stores your data as key-value pairs, where the key is the name of the file and the value is the content of the file. Also, it uses buckets (directories) to store your objects (files).
Essential S3 takeaway points
- It is object-based
- Files can range from O Bytes to 5 TB
- You have unlimited storage
- Data is stored in buckets
- Buckets must have unique names because the S3 namespace is universal – that means, there cannot be two buckets with the same name in the world
- When an object is uploaded successfully in the bucket, it returns the status code 200
S3 Storage Classes
AWS S3 is a complex service, and you can use it for different uses cases such as archiving your data, simply storing your data and so on. As a result, it has different storage classes for different uses cases.
- S3 Standard
- This storage class comes with 99.99% availability and 99.999999999% durability.
- It stores your data on multiple systems across multiple facilities to sustain the loss of two facilities at the same time
- It replicates the data across three availability zones, at least
- S3 IA (Infrequently Accessed)
- This storage class is for data that is infrequently accessed but requires quick access when it is needed.
- Even though it is cheaper than the standard storage, it charges you per file retrieval.
- S3 One Zone IA
- It is almost the same thing as S3 IA with the only difference being that your data is stored in one place only – no multiple AZs.
- It applies a retrieval fee when you retrieve your data.
- S3 Intelligent Tiering
- This storage class automatically moves your data to the most cost-efficient storage tier. E.g. it could push your data from S3 Standard to S3 One Zone IA to reduce costs.
- It does not impact performance.
- S3 Glacier
- S3 Glacier is suitable for data archiving where retrieval times between minutes to hours are accepted.
- It is the second-lowest-cost storage class.
- S3 Glacier Deep Archive
- It is the same as S3, with one significant difference: data retrieval takes twelve hours.
- It is also the lowest-cost storage class.
S3 Security
By default, all the S3 buckets you create are private. In other words, they are not available to the public; nobody can access them if you give them the link. You have to change the permissions to allow people to access your S3 objects.
There are three ways to control access to AWS S3 resources:
- IAM policies => Specifies the access of a specific user - e.g. what API calls are allowed from that user.
- Bucket Policies => What can be done and what cannot be done on the S3 bucket. It enables cross-account access to the buckets.
- Access Control Lists => The rules are set at the object level.
Access Control Lists
What is the difference between these three? First of all, ACLs (Access Control Lists) is a legacy mechanism to control access to objects and buckets. However, ACLs are not deprecated, and you can still use them if you find them sufficient to control access.
What is an ACL? You attach an ACL to your S3 bucket or object, and it defines the accounts and groups that have access to them. It also specifies the type of access these accounts and groups have to your buckets and objects. It is also important to note that you can attach different ACLs to the objects within the same bucket.
 An example of AWS S3 Access Control List (source: AWS docs)
An example of AWS S3 Access Control List (source: AWS docs)
The figure above shows ACLs in action.
Bucket Policies
Nevertheless, AWS recommends using S3 Bucket Policies or IAM policies to control access to your objects and buckets. As you can infer from the name, Bucket Policies apply only to S3 buckets. As a result, you cannot apply Bucket Policies to an individual object.
Using AWS S3 Bucket Policies, you can allow or deny people different actions on the bucket you attach these policies to. For instance, you can allow users to PUT (upload) objects in the buckets, but you can deny them to DELETE objects from the bucket. Let us look at the JSON code snippet below:
{
"Id": "Policy1598344479626",
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1598344475395",
"Action": [
"s3:CreateBucket"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::catalinsbucket",
"Principal": "*"
}
]
}
We can look at the Action, Effect, Resource and Principal fields to understand what the policy does. Looking at the Action and Resource fields, we can see that it is about creating buckets. The resource also tells us that it applies to the bucket called catalinsbucket. Then, the Effect and Principalfields tells us that it allows everyone to create buckets.
Of course, the policies can become more complicated, but you get the idea.
IAM Policies
IAM Policies are a bit different in the sense that you use them to allow or deny actions on various AWS resources. You apply these policies to IAM users, groups, or roles. In simpler words, these policies specify what a user, group or role can do in your AWS environment.
Thus, what is the difference between IAM and Bucket policies? You apply Bucket Policies to a bucket. On the other hand, you apply IAM Policies to a user/group/role. Let us look at an example again.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1598345611625",
"Action": [
"s3:PutObject"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::catalinsbucket"
}
]
}
We can infer from the code snippet what this policy is about, exactly like with the Bucket Policy from above. However, there is one difference. For the IAM policy, we do not have a Principal because this policy is applied to a user/group/role. The reason for this is that we apply the policy to a principal, so it is redundant to specify it. Also, by looking at the policy, we can see that the specific user/group/role is allowed to upload files to the bucket catalinsbucket.
When to use one over the other
If you want to control what a user can do in your AWS environment, you should probably use an IAM policy. If you want to control who can access your S3 buckets, you should probably use a Bucket Policy.
S3 Encryption
It allows you to set necessary encryption behaviour for your S3 buckets. Encryption is vital because it protects your data from being stolen. As an example, let us say someone hacks into the AWS servers, and get access to your data. You do not want them to read your data. Therefore, AWS offers various methods of encrypting your data in S3. By default, AWS S3 uses SSL/TSL.
There are four types of server-side encryption:
- SSE-S3 => It uses the AES-256 algorithm, and AWS handles the keys. S3 uses a unique key to encrypt each object.
- SSE-KMS => You can choose a CMK (customer master key) which you can create and manage, or you can choose CMK that is managed by AWS. The keys for encrypting the data are stored alongside the data they protect. The security controls in AWS KMS are beneficial if you need to meet compliance requirements related to encryption.
- SSE-C - You, as a customer, manage the keys, which means that AWS S3 does not store the keys. You have to keep track which object uses which encryption key.
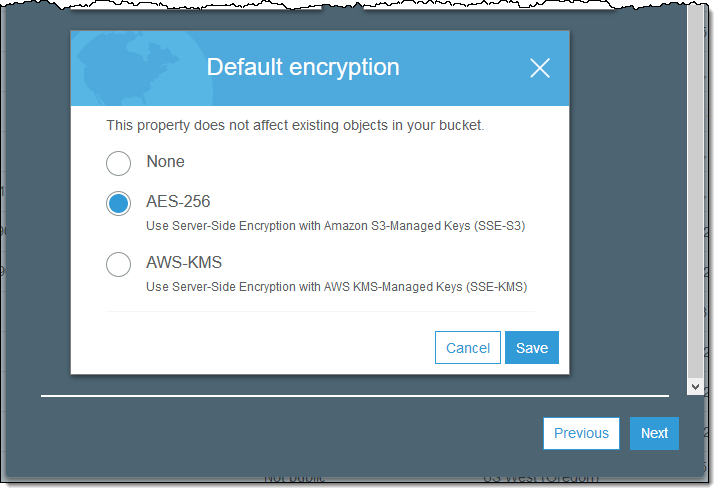 Example of AWS S3 Encryption Options (source: AWS docs)
Example of AWS S3 Encryption Options (source: AWS docs)
Besides these, there is also client-side encryption, which means that you encrypt the data before uploading it to S3. With client-side encryption, you can store the master key (CMK) in AWS Key Management Service (AWA KMS), or you save a master key within your application. You are solely responsible for encrypting and decrypting the data.
S3 Data Consistency
Data consistency is a vital topic. We have two questions:
- What happens when we upload a new object to S3?
- What it happens when we update/delete an existing object from S3?
Let us start by uploading new objects to S3. For this, we have "Read After Write Consistency". In simpler words, that means we can access the objects straightaway after uploading them. You upload an image, and you can access it straight away.
What happens when we update or delete existing objects? In this case, we have "Eventual Consistency". In other words, that means we might get the old object after updating it. Also, after deleting an object, we might still be able to access it for a while. Why is that happening? That is because it takes time for the changes to propagate as the data in S3 buckets are spread across multiple devices and facilities.
That is all about data consistency in AWS S3.
Cross-Region Replication (CRR)
This feature allows you to make copies of your S3 objects in a different AWS region easier. To use the "Cross-Region Replication" feature, you must have versioning enabled because it is built on top of it.
Once you enable this feature, you can choose a destination bucket from another AWS region to automatically replicate all the objects uploaded to a specific S3 bucket. The beautiful thing about this feature is that it also copies the metadata and the Access Control Lists with the objects.
Cross-Region Replication is a fantastic feature because it provides higher durability, lower latency access and potential disaster recovery for your data.
S3 Versioning

Versioning Example (source: AWS docs)
All "versioning" means is to keep multiple variations of the same object in the same bucket. Why would you do that? Having different versions of the same object, you can quickly recover from application failures and accidental deletion or overwrite. Be aware that you cannot disable the feature once you enable it. You can only suspend it.
Once you enable the feature, each object has a unique version ID assigned to it. For instance, the same image "catalin_profile.jpg" has different version IDs. You can upload the same object multiple times, and there will be numerous instances of it with different IDs. When you overwrite the object, it results in a new object version. When you delete an object, S3 inserts a delete marker, instead of removing the object permanently.
For extra security, you can enable multi-factor authentication (MFA). What that means is that S3 requires additional authentication to change the versioning state of the bucket and to delete an object version permanently.
S3 Lifecycle Management
Everybody cares about costs, and sometimes your objects might use a cost-ineffective storage class. What this feature allows you to do is to automate the process of moving your objects to a more cost-effective storage class or delete the objects altogether.
With transition actions, you define when objects should transition to another storage class. For instance, you might want to move your data to S3 Glacier after a year. With expirations actions, you can define when your objects expire. Once the objects expire, S3 deletes them.
This feature is handy to manage your costs effectively. It automatically moves your data for you to a more efficient class-storage, helping you to save money.
Transfer Acceleration
In the simplest terms, AWS S3 transfer acceleration allows faster transfer of files over long distances between the end-user and the bucket. Transfer acceleration takes advantage of CloudFront's edge locations, distributed globally, to enable quick and secure file transfer over long distances.
How that works? Instead of uploading to a bucket, the user uses an edge location URL to upload the files. Once the files arrive at the specific edge location, S3 uses an optimised network path to route the data to the user's bucket.
Why would you use this feature?
- You have users that upload to a bucket from all over the world.
- You transfer gigabytes or terabytes of data across continents regularly.
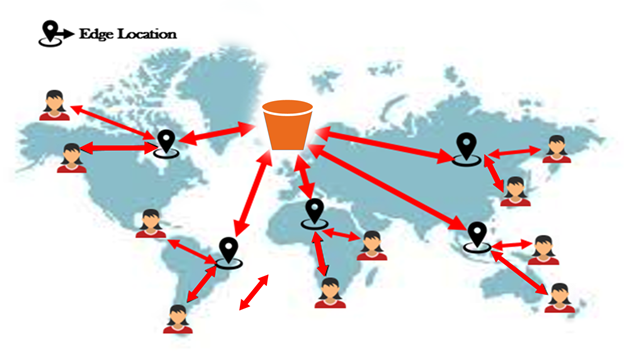 Transfer Acceleration Example (source: Medium)
Transfer Acceleration Example (source: Medium)
The above picture illustrates the feature better. The user uploads the files to the closest edge location to them, and AWS takes care of routing that data from the edge location to an S3 bucket over an optimised network path. That is all.
Conclusion
In conclusion, AWS S3 is a service you need to be comfortable with, especially if you are looking to take the exams. In this article you learnt about:
- What S3 is
- S3 use cases
- S3 storage classes
- Security and encryption in S3
- Lifecycle Management
- Data Consistency
Learn AWS from scratch and become a cloud engineer with the AWS Certified Cloud Practitioner course.